|
|||||||||||||||||||||||
Intel Math Kernel Library Performance Specifications
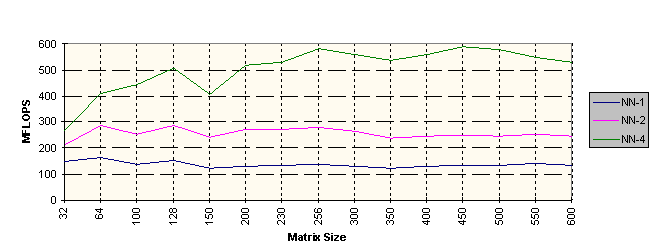
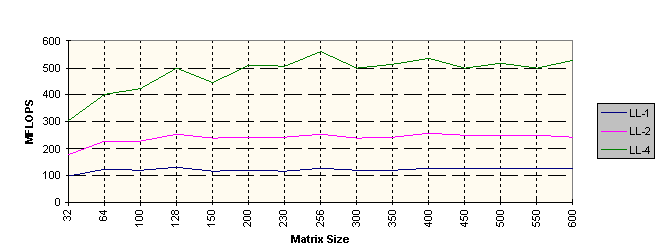
All of the Math Kernel Library routines have been optimized for high performance on the Pentium® and Pentium Pro processors. The BLAS level 3 routines that perform matrix-matrix operations have been further optimized for efficient cache usage. This optimal cache management ensures excellent performance on a single processor. In addition, these routines have been multithreaded and scale well when run on up to four processors. The graphs that follow show double precision performance on two of the BLAS level 3 routines: DGEMM and DSYMM run on 200 MHz Pentium Pro Processor. DGEMM computes a double-precision general matrix-matrix multiplication, while DSYMM computes double-precision symmetric matrix-matrix multiplication. For DGEMM, NN indicates a normal orientation for each matrix. For DSYMM, LL means that the symmetric matrix is on the left and its lower portion is used. For both functions, -1, -2, and -4 represent one, two, and four processors, respectively.
|
Legal Stuff © 1997 Intel Corporation
