
| Information in this document is provided in connection with Intel products.
No license, express or implied, by estoppel or otherwise, to any
intellectual property rights is granted by this document. Except as provided
in Intel's Terms and Conditions of Sale for such products, Intel assumes no
liability whatsoever, and Intel disclaims any express or implied warranty,
relating to sale and/or use of Intel products including liability or
warranties relating to fitness for a particular purpose, merchantability, or
infringement of any patent, copyright or other intellectual property right.
Intel products are not intended for use in medical, life saving, or life
sustaining applications. Intel may make changes to specifications and
product descriptions at any time, without notice. Copyright © Intel Corporation (1996). Third-party brands and names are the property of their respective owners.
|
The Z-Buffer is a hidden surface removal algorithm commonly used in 3D applications that require accurate representation of intersecting planes such as joints and trusses. A hidden surface removal algorithm determines whether the pixel is hidden by others in the scene closer to the viewer. For example if the z value of a pixel is greater than the one already drawn for a given x,y location then the pixel is not drawn. Most CAD systems, architecture visualization engines, and high-end rendering engines use the Z-Buffer technique to provide accurate polygon based renderings. In fact, the Z-Buffer algorithm is an integral component of 3D hardware accelerator cards and a software component of Criterion's RenderWare*, Argonaut's BRender*, and Microsoft's Direct3D*. This application note will provide an overview of the 3D Z-Buffer algorithm , two methods for implementing a Z-Buffer using MMX™ technology, optimization techniques, and performance results. For demonstration purposes the sample code provided in Section 4 operate on a signed 16-bit Z-Buffer with 16-bit (565) color values using flat shading. This method processes four pixels in the Z-Buffer utilizing the MMX instruction PCMPGTW, which operates on signed words.
A Z-Buffer stores the depth values of a 3D object displayed in a viewport. When a 3D polygon is drawn on the screen it consists of x, y, and z values, one set per pixel on the screen. The Z-Buffer holds the depth value of the nearest polygon that has been drawn. Before a polygon is rendered to the display, the z values for pixels already drawn on the screen must be fetched from the buffer, compared to new values, and conditionally updated. Figure 1.1 and 1.2 shows a mouse rendered with and without Z-Buffer hidden surface removal. A Z-Buffer with the positive Z-axis pointing into the screen was used for all the examples in this appnote. However sample code for both orientation of the Z-axis is provided in Section 4.2.
|
| |
Figure 1.1 Z-Buffer Hidden Surface Removal | Figure 1.2 No Hidden Surface Removal |
The Z-Buffer consists of a block of contiguous memory allocated to match the size of the screen in which the 3D polygons are rendered. A Z-Buffer comprised of signed words initialized to 0x7fff(see Figure 2.1) is used to store the z values. This provide a dynamic range spanning -32,768 at the screen to 32,767 at infinity.
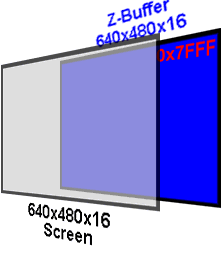
Figure 2.1 Z-Buffer Allocation
For 3D rendering, polygons are rasterized into spans by interpolating the edges of the polygon from the vertices. In Figure 2.2 vertices (Smallx, Y, Z1[Y]) and (Largex,Y,Z2[Y]), which describe the span, are interpolated from the polygon edges formed from the vertices (B,C) and (A,E).
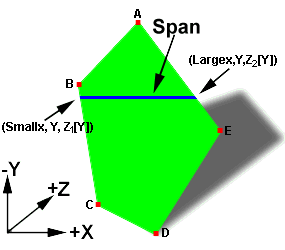
Figure 2.2 Bilinear Interpolation
In order to maintain the correct view for intersecting polygons, each z value in the span is checked against the value
in the Z-Buffer. If the z value is closer to the viewer (signified by a smaller number) then the pixel is displayed and the
value in the Z-Buffer is replaced by the new pixel's z value. Since a span is specified by two vertices,(Smallx, Y,
Z1[Y]) and (Largex,Y,Z2[Y]), the z value is interpolated by calculating the change in z (![]() Z) per x increment (
Z) per x increment ( ![]() X)
as shown in Figure 2.3.
X)
as shown in Figure 2.3.
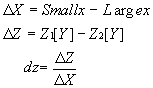
Figure 2.3 Z Interpolation for a Span
After dz is obtained from the previous equation, the Z-Buffer algorithm in Figure 2.4 is executed. Only pixels on the span which possess a lesser z value then those contained in the array zbuffer are drawn.
z=Z1[Y];
for(x=Smallx; x<Largex+1; x++){
if(z < zbuffer[x,Y]){
zbuffer[x,Y]=z;
DrawPixel(x,Y,polygoncolor);
}
z+=dz;
}
Figure 2.4 Pseudo-Code for Z-Buffer Algorithm
|
The pseudo-code is a C implementation of the Z-Buffer algorithm, where compares operate in serial for each pixel in the span and drawn to the screen. Note that no clamping is used for the code in Figure 2.4 which may cause z values at the extremes of the signed word (0x7fff and 0x8000) to change signs. However MMX technology implementations do not have this problem because clamping is done through sign saturate MMX instuctions. The SIMD(Single Instruction Multiple Data) architecture, in MMX technology, is exploited by using a PCMPGTW to compare four z values with four Z-Buffer values. A mask is obtained from the operation, shown in Figure 2.5, and used to update the screen and Z-Buffer.

Figure 2.5 PCMPGTW Mask Result
Since MMX instructions access multiple words, the start of the span must be eight byte aligned. The implication is that spans which start at unaligned Z-Buffer addresses (those addresses which do not end with zero or eight) will cause a penalty for each access to memory. Since a span and its respective Z-Buffer can start between aligned addresses, a span alignment algorithm is used.

Figure 2.6 Mixed vs. MMX Procedure
Figure 2.6 provide an example of an unaligned start address. The span alignment procedure always operate on eight bytes of data, and thus the start address is adjusted to an aligned memory location in the Z-Buffer. The unrelated Z-Buffer information, marked by "X", is read in and written out without changes. This method is explained in-depth in Section 2.2.3 - Span Alignment.
In the following discussion, each start address of the span is assumed to be eight byte aligned in the Z-Buffer. There are two methods for rendering pixels onto the screen as described in Section 2.1.2 - Pixel Merging and Section 2.1.3 - Transparent Blit.
The PCMPGTW is used to generate a mask for use in either Pixel Merge or Transparent Blit. This instruction operate on data from the Z-Buffer and interpolated z values shown in Figure 2.3. In order to operate on four z values at once, the initial z value is placed in a MMX technology register(mm0) and propagated into the four words of the register. Then a 64-bit register(mm1) containing increment constants (offset) is added to the four words, creating the appropriate z values for the four pixels. Next the values in the Z-Buffer are copied into the mm3 register. The pcmpgtw compare instuction is executed for mm3 and mm0, creating a mask of 0xffff where the Z-Buffer values are greater than the z values. The resulting mask is applied to either Pixel Merge or Transparent Blit. To prepare for the next four pixels, the z values in mm0 is incremented by fourdz(see Figure 2.7).
Initial Variables ;zval=Z[Y] ;fourdz=[4*dz|4*dz|4*dz|] ;offset=[0|dz|2*dz|3*dz] | |
movq mm0,dword ptr[zval] punpcklwd mm0,mm0 punpckldq mm0,mm0 movq mm1,dword ptr[offset] paddsw mm0,mm1 check_zvalues: movq mm1,dword ptr[zbuffer] pcmpgtw mm1, mm0 : : ;do Transparent Blit or Pixel Merge : paddsw mm0,dword ptr[fourdz] jmp check_zvalues Figure 2.7 Z Value Calculation Algorithm - Unoptimized |
In the Pixel Merge method (illustrated in Figure 2.8.), color for the span is loaded into a MMX technology register(mm3) and propagated into the four words of the register(color propagation is only necessary for flat shaded polygons). A copy of the register mask in mm0 is placed in mm2 and PANDNed with mm3 causing pixels with larger z values than the Z-Buffer to copy over to mm2. Next the PAND operation is performed with the screen memory and mm0, allowing pixels with smaller Z-Buffer values through. Then mm0 is PORed with mm2 and copied to the back buffer where previous polygons were drawn. After all the polygons are processed for the scene, the back buffer is blitted to the frame buffer for display.
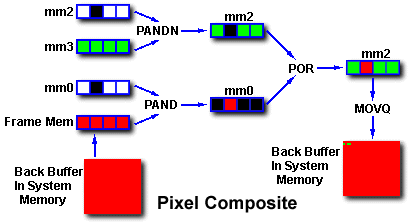
Figure 2.8 Pixel Merging Method
Similar to the Pixel Merge method, the color of the span is placed into mm3. A PANDN operation is performed on the original mask mm0 and copied to a temporary buffer. The temporary surface may contain previous span information for the polygon(shown by other green pixels in Figure 2.9). After the whole polygon is processed, the surface is blitted, with black as the transparent color, to the back buffer. This differs from Pixel Merge, where a complete scene is placed in the back buffer. Black transparency blitting is vital in removing the PAND instruction from the algorithm, since PCMPGTW automatically generates 0 as a false result. However, polygons described by black will also be treated as part of the transparent color and therefore will not show up in the final image. For optimal performance, only the rectangle bounding the polygon should be blitted from the temporary buffer to the back buffer. The advantage of Transparent Blit over Pixel Merge is the speed gained from not having to access the frame memory for compositing the pixels. But, Transparent Blit will fail for black polygons and speed will be lost if more then the rectangle bounding the polygon is blitted from the temporary buffer to the back buffer.
![]()
Figure 2.9 Transparent Blit Method
This section discusses the importance of back buffer location, memory alignment, and span alignment optimization techniques. This comprehensive optimization approach applied to the Z-Buffer algorithm provides an increase in performance(10% to 60%) over traditional C and assembly code.
As stated earlier, in Section 2.1, the back buffer is the repository for the video display. This buffer can be allocated in either system or video memory. The location of the back buffer plays an integral part in the performance of the two MMX Z-Buffer routines. Table 1 shows the performance impact for changes in back buffer location versus the Z-Buffer method used.
| Video Memory | System Memory | |
| Pixel Merge | Very Slow | Average |
| Transparent Blit | Average | Fast |
Table 1 Display Buffer Location Vs. Z-Buffer Method
Pixel Merge is not useful when the back buffer is in video memory because of the overhead associated with accessing the PCI bus for pixel information in video memory. This problem can be avoided in Transparent Blit because the algorithm avoids reads from the back buffer. Performance numbers for both Z-Buffer algorithms in system memory and video memory are provided in Section 3.2.2.
This section is a quick primer for data alignment issues in relation to data lengths, data structures, and memory allocation. In the process of writing a modeling shell for the Z-Buffer algorithm, a number of data related issues arose from the interaction of C++ with assembly. Data length describes the datatypes used in relation to the programming platform. In a 32-bit programming environment it is best to use 32-bit datatypes, while 16-bit datatypes are desirable for 16-bit applications. If a 32-bit datatype is used in a 16-bit program and visa versa, a one to three cycle prefix penalty is incurred each time the data is accessed and used.
Second, data structures should be placed from largest datatype to smallest datatype. By placing datatypes inside a structure using this method, memory misalignments are reduced. Memory misalignment is also important in memory allocation which describes both arrays and malloc's(or new's). The rule of thumb here is to allocate more memory than is required and use a pointer to access the memory starting with an aligned address, as shown in Figure 2.10. By aligning memory allocations, a three cycle penalty is avoided for each memory access.
char *alignedmem, *somemem; somemem = malloc(1024+7); alignedmem = (char*)((dword)(somemem+7)&~7); Figure 2.10 8-Byte Malloc Alignment |
Span alignment consists of a start and end masking of excess Z-Buffer data and an adjustment offset increment. Figure 2.11 shows an unaligned span with excess data shown as a white X on black.
Figure 2.11 Aligned Processing
The data in the aligned Z-Buffer are processed in the normal fashion described in Figure 2.7. However the start and end processing of the span consists of a mask offset. In front alignment the three least significant bits are used in a look up table (see table 2) for masking bits while the address of the span is ANDed with 0xFFFFFFF8 to the obtain the proper aligned address. The mask is then ORed with the compare result to prevent unwanted data from copying over during the POR process described in Section 2.1.
Table 2 Start Look Up Table | |||||||||||
Since the original zval, described in Figure 2.7, is always located at the beginning of the register, it must be moved to match the start of the misalign address. A table look up is used to find the proper value to subtract from the offset, such that zval appears in the proper position. Table 3 shows the values used to modify the offset.
Table 3 Offset Modifier Look Up Table | |||||||||||
For example, if the span address starts at 0x680f4 then its aligned address starts at 0x680f0. Because of the alignment, the initial z value is now associated with address 0x680f0 instead of 0x680f4. There the initial z value must be shifted to the proper positions by subtracting 2*dz to all four words in the MMX register. This results in moving the initial z value from position zero in the MMX register to position two. For end alignment, the address is already aligned, however the end pixels may not need to be processed. In this case, a look up table is used based on the number of pixels left to do(see table 4). Just like front alignment, the mask is then ORed with the compare result to prevent unwanted data from copying over during the POR process.
Table 4 End Look Up Table | |||||||||||
Performance measurements for the Z-Buffer algorithms consist of static analysis using V-Tune and dynamic analysis under system conditions. The results were obtained using a prototype Pentium Processor with MMX Technology. In static analysis, only the core Z-Buffer compare cycles were analyzed. Dynamic analysis provided information regarding the execution of the routine in relation to the interaction between the CPU, cache, and memory.
The following results were obtained from VTune using the code in Section 4. The following table shows the typical trade off between MMX technology enabled code length versus standard assembly code length. To obtain the optimal performance from MMX instructions, the Z-Buffer procedure execute data setup cycles once per polygon to ensure that four words are operated on. Scalar(standard) assembly operate on a single word, eliminating the requirement for alignment and data setup resulting in shorter assembly code. However 5 cycles of prefix penalty exist in the scalar assembly inner loop because of word data is used in a 32-bit program. Table 5 illustrates the total cycle count for each version of the Z-Buffer algorithm. These instruction counts and cycles take into account of the entire Z-Buffer procedure.
Table 5 Static Analysis of Z-Buffer Procedures | |||||||||||||||||||||
Since the majority of execution time is spent in the inner loop (shown in Figure 2.4) the cycle counts for the loop are provided below. Two scalar cycle counts are provided because of the conditional statement which exists inside the loop. Thus performance is affected depending on the jump condition. The MMX technology Z-Buffer procedures do not contain the jump because data is always written back to the Z-Buffer. The number of times these loops are executed is dependent on the length of the aligned span. Section 3.2.1 provides data on span length versus execution time.
Table 6 Static Analysis of Inner Loops | |||||||||||||||||||||||||
Two methods were used to obtain dynamic execution results. The first method involved examining the performance of the z value compare instructions for an eight byte aligned span in the Z-Buffer algorithm. The second method consisted of implementing the Z-Buffer algorithm in a graphics engine to simulate system conditions.
A single aligned span was examined in Figure 3.1. The results below show the optimal performance of MMX instruction enabled Z-Buffer procedure compared to standard assembly and C. The data reinforces the fact that the MMX technology Z-Buffer procedure will gain the most benefit from large spans.
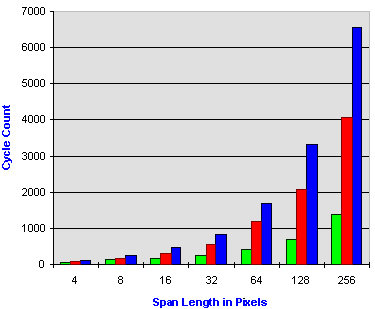

| 4 Pixels | 8 Pixels | 16 Pixels | 32 Pixels | 64 Pixels | 128 Pixels | 256 Pixels | |
| MMX Technology Gains Versus Scalar Assembly | 1.29X | 1.40X | 1.88X | 2.16X | 2.90X | 2.93X | 3.00X |
| MMX Technology Gains Versus C | 1.81X | 1.94X | 2.94X | 3.36X | 4.15X | 4.69X | 4.83X |
Figure 3.1 Optimal Z Compare Performance
A 3D graphics engine was written to test the system performance of the Z-Buffer algorithm. Four 3D models (shown below) were created to test the performance of the Z-Buffer in the four conditions shown in table 1(system vs. video memory and Pixel Merge vs. Transparent Blit).
 |  |
Intersecting Rectangles (Isect) | Cylinder |
 |  |
Zeppelin | Mouse |
Figure 3.2 Objects Used for Performance Analysis | |
The models were rendered in a viewport of size 480x480 with 16-bit color using flat shading ,aligned Direct Draw Surfaces and aligned Z-Buffer blocks. The blitting from the back buffer to the frame buffer were not timed, since they are similar in all three Z-Buffer algorithms. The result of the four tests are provided in Section 3.2.2.1 and 3.2.2.2. In all four cases, the L1 cache played a minimal part in the performance of the Z-Buffer, due to the large size of the Z-Buffer. For example a 480x480 display surface uses 450 Kilobytes (480x480x2 bytes) of memory for the Z-Buffer. Due to the size of the Z-Buffer, information in the cache is seldom used more than once resulting in cache thrashing.
Using a back buffer allocated from system memory, provides better performance for both MMX technology Z-Buffer algorithms because display surface memory reads are not routed through the PCI bus. From the performance results shown in Figure 3.3 and 3.4, MMX instruction based Z-Buffers are efficient in models with large polygons such as Isect. This is especially true for Pixel Merge, where reads offset the benefit of the SIMD architecture in small polygon models such as the mouse.
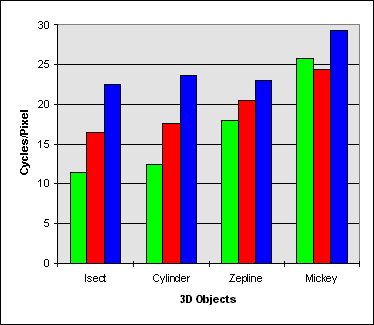
| Isect | Cylinder | Zeppelin | Mouse | |
| MMX Technology Gains Versus Scalar Assembly | 1.45X | 1.42X | 1.14X | 0.95X |
| MMX Technology Gains Versus C | 1.99X | 1.91X | 1.28X | 1.14X |
Figure 3.3 Pixel Merge in System Memory
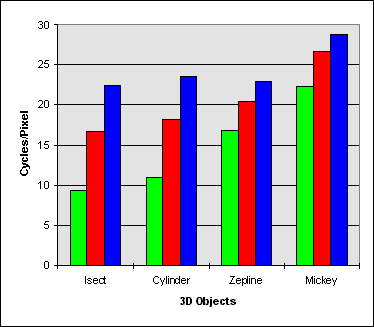
| Isect | Cylinder | Zeppelin | Mouse | |
| MMX Technology Gains Versus Scalar Assembly | 1.78X | 1.67X | 1.22X | 1.20X |
| MMX Technology Gains Versus C | 2.41X | 2.15X | 1.37X | 1.29X |
Figure 3.4 Transparent Blit in System Memory
Changing the back buffer from system memory to video memory is detrimental to the performance of MMX technology Z-Buffer procedures. As stated earlier, reads from the PCI bus limits the efficiency of Pixel Merge and Transparent Blit Z-Buffer algorithms. Pixel Merge Z-Buffer is affected the most from using a display surface in video memory. Pixel Merge reads from the display memory during execution, shown in Figure 2.6, causing penalty cycles from the PCI bus. Transparent Blit Z-Buffer is affected less than Pixel Merge Z-Buffer because only writes are executed on the back buffer.
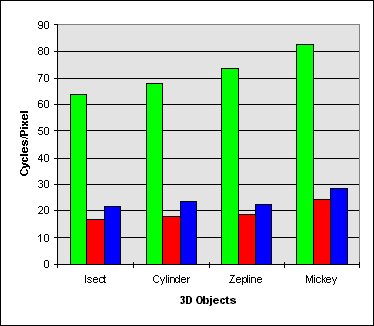
| Isect | Cylinder | Zepplin | Mouse | |
| MMX Technology Gains Versus Scalar Assembly | 0.26X | 0.26X | 0.25X | 0.29X |
| MMX Technology Gains Versus C | 0.34X | 0.34X | 0.31X | 0.34X |
Figure 3.5 Pixel Merge in Video Memory
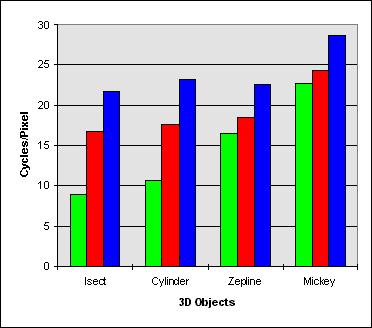
| Isect | Cylinder | Zeppelin | Mouse | |
| MMX Technology Gains Versus Scalar Assembly | 1.86X | 1.66X | 1.13X | 1.07X |
| MMX Technology Gains Versus C | 2.42X | 2.18X | 1.38X | 1.26X |
Figure 3.6 Transparent Blit in Video Memory
TITLE asm_zbuffer ;**************************************************************************** ; This program was assembled with Microsoft MASM 6.11d ;**************************************************************************** .nolist .list .586 .model FLAT ;**************************************************************************** ; Code Segment Declarations ;**************************************************************************** .code ;**************************************************************************** ; void asm_zbuffer(long smallx, long largex, long zval, long dz, ; long col,ZBUFTYPE *zbuf, WORD *dds ); ; vars: ; smallx - holds the small x value of the span ; largex - holds the large x value of the span ; zval - holds the intial z value of the span ; dz - delta z is added to zval to show change as the span increments from ; smallx to largex ; col - 16bit(usually 565) color to be placed in the direct draw surface ; zbuf - a pointer to the z-buffer memory location ; dds - pointer to the direct draw surface ; ; procedure: ; asm_zbuffer checks the zbuffer for the span, specified by smallx and largex ; and fills in the appropriate pixels in the direct draw surface. ; This algorithm uses flat shading algorithm and 16it color depth. ; it does not handle z value clamping which may cause inaccurent span ; drawings for z values close to the extremes of 16bit datatype. The ; parameters are 32bit values so that penalties aren't incurred on access. ;**************************************************************************** asm_zbuffer PROC C USES esi edi eax ebx ecx edx, smallx:DWORD, largex:DWORD, zval:DWORD, dz:DWORD, col:DWORD, zbuf:PTR WORD, dds:PTR WORD mov edx, largex ;copy largex into a reg mov ebx, smallx ;copy smallx into a reg inc edx ;largex+1 sub edx, ebx ;largex-smallx mov eax, zval ;copy initial z value into a reg mov esi, zbuf ;copy zbuffer address into reg mov edi, dds ;copy dds address into reg mov ecx, col ;copy color into a reg SINGLE_PIXEL_LOOP: cmp ax, word ptr [esi+2*ebx] jg NO_UPDATE ;jmp on zval>zbuf mov word ptr [esi+2*ebx], ax ;copy zval to zbuf mov word ptr [edi+2*ebx], cx ;copy color to direct draw surface NO_UPDATE: add eax, dz ;add zval with dz inc ebx ;increment memory offset pointer ;used for zbuf and dds dec edx ;one pixel down jnz SINGLE_PIXEL_LOOP ;go back and do next pixel ret asm_zbuffer EndP END
TITLE mmx_zbuffer ;**************************************************************************** ; This program was assembled with Microsoft MASM 6.11d ;**************************************************************************** .nolist INCLUDE iammx.inc .list .586 .model FLAT ;**************************************************************************** ; Data Segment Declarations ; ; vars: ; sxmask0 - dummy place holder for smallx masking of don't care values ; sxmask1 - mask of don't care values for 1 to 3 pixel misalignment of smallx ; sxmask2 this allows processing of 4 pixels and operating on those pixels ; sxmask3 that is part of the span. ; lxmask0 - dummy place holder for largex masking of don't care values ; lxmask1-3 works the same was as sxmask but is applied to the end of the span ; three_two_one_zero constant used to multiply initial zval with in setup_mmx_zbuf ; most_neg_mask used in the alignment of smallx and largex for z-buffers with ; positive z axis coming out of the screen ; most_pos_mask used in the alignment of smallx and largex for z-buffers with ; negative z axis coming out of the screen ; POSZ_INTOSCR determines if pos z points into the screen(1) or out of the screen ;**************************************************************************** .data sxmask0 QWORD 0ffffffffffffffffh sxmask1 QWORD 0ffffffffffff0000h sxmask2 QWORD 0ffffffff00000000h sxmask3 QWORD 0ffff000000000000h lxmask0 QWORD 0000000000000000h lxmask1 QWORD 000000000000ffffh lxmask2 QWORD 00000000ffffffffh lxmask3 QWORD 0000ffffffffffffh three_two_one_zero QWORD 0003000200010000h most_neg_mask QWORD 08000800080008000h most_pos_mask QWORD 07fff7fff7fff7fffh POSZ_INTOSCR EQU 1 ;**************************************************************************** ; Code Segment Declarations ;**************************************************************************** .code ;**************************************************************************** ; void setup_mmx_zbuf ( long dz, long col, short* mmxvar) ; vars: ; The vars passed in are longs because of penalties for 16bit access ; only the first 16bit contain valid data. ; dz - amount to increment the initial zvalue with to genererate the next zvalue ; col - the 16-bit color value to be displayed for this polygon ; mmxvars - an array of shorts which is loaded with the following: ; 0--------------------- ; |0 |1*dz|2*dz|3*dz| ; 8--------------------- ; |1*dz|1*dz|1*dz|1*dz| ; 16--------------------- ; |2*dz|2*dz|2*dz|2*dz| ; 24--------------------- ; |3*dz|3*dz|3*dz|3*dz| ; 32--------------------- ; |4*dz|4*dz|4*dz|4*dz| ; 40------------------------- ; |color|color|color|color| ; ------------------------- ; ; eax - unused ; ebx - unused ; ecx - unused ; edx - unused ; esi - holds a pointer to mmxvars ; edi - unused ; mm0 - unused ; mm1 - used to create elements in mmxvars ; mm2 - used to create the initial dz increment for 4 pixels ; mm3 - used to create elements in mmxvars ; mm4 - unused ; mm5 - unused ; mm6 - holds the four copies of the polygon color ; mm7 - unused ; ; procedure: ; This function is called once every polygon to fill in the proper delta z for ; use in span alignment. It also fills in an array for 16bit flat shading. The ; data structure is used in the functions mmx_merge_zbuffer and mmx_trans_zbuffer. ;**************************************************************************** setup_mmx_zbuf PROC C USES esi edi eax ebx ecx edx, dz:DWORD,col:DWORD,mmxvars:PTR WORD movd mm1, dword ptr [dz] ; move dz into mm1 movd mm6, dword ptr [col] punpcklwd mm1, mm1 mov esi,mmxvars punpckldq mm1, mm1 movq mm2, mm1 punpcklwd mm6, mm6 pmullw mm2, dword ptr [three_two_one_zero] punpckldq mm6, mm6 movq dword ptr [esi+8], mm1 ;zumask1 movq mm3,mm1 movq dword ptr [esi+40], mm6 ;color paddsw mm1, mm1 movq dword ptr [esi], mm2 ;zu_incr paddsw mm3, mm1 movq dword ptr [esi+16], mm1 ;zumask2 paddsw mm1, mm1 movq dword ptr [esi+24], mm3 ;zumask3 movq dword ptr [esi+32], mm1 ;four_zu ret setup_mmx_zbuf EndP ;**************************************************************************** ; VOID mt_state (VOID) ; procedure: ; This function is called once per polygon to clear out the mmx register states. ; Although function can be called once per rasterization scene, it is best to call ; it often in a multitasking/threading environment since who knows what may be ; running in the background while the rasterization takes place ;**************************************************************************** mt_state PROC C emms ; empty the MMX register state ret mt_state EndP IF POSZ_INTOSCR ;choose which version of mmx zbuffer to compile ;**************************************************************************** ; The following versions of mmx zbuffer is used when the positive z ; axis points into the screen. -32K is at the screen and receeds to ; 32K in the distance. ;**************************************************************************** ;**************************************************************************** ; Pixel Merging Algorithm for positive z axis going into the screen ; void mmx_merge_zbuffer ( long smallx, long largex, long zval, long dz, ; unsigned long col, short* zbuf, word* dds, short *mmxvar) ; vars: ; most variables are hold 16bit data but are passed as 32bit to prevent penalties in ; the scalar_asm function ; smallx - pixel offset for the start of the scan line ; largex - pixel offset for teh end of the scan line ; zval - the z-value for the first pixle in the span ; dz - amount to increment the initial zvalue with to genererate the next zvalue ; col - the 16-bit color value to be displayed for this polygon used in scalar asm ; zbuf - pointer to the start of this row in the z-buffer array ; dds - pointer to the start of this row in the offscreen surface ; mmxvars - an array of shorts which is loaded with the following: ; 0--------------------- ; |0 |1*dz|2*dz|3*dz| ; 8--------------------- ; |1*dz|1*dz|1*dz|1*dz| ; 16--------------------- ; |2*dz|2*dz|2*dz|2*dz| ; 24--------------------- ; |3*dz|3*dz|3*dz|3*dz| ; 32--------------------- ; |4*dz|4*dz|4*dz|4*dz| ; 40------------------------- ; |color|color|color|color| ; ------------------------- ; ; eax - aligned smallx ; ebx - smallx ; ecx - aligned largex-smallx ; edx - largex ; esi - pointer to the z-buffer ; edi - pointer to the offscreen surface ; mm0 - the 4 z-values to compare with z-buffer ; mm1 - a copy of the compare mask ; mm2 - holds zbuffer values and later compare masks ; mm3 - a copy of the compare mask ; mm4 - holds the four copies of the polygon color ; mm5 - misc. functions ; mm6 - copy of mm4 used with compare mask ; mm7 - holds mm0 with modified zvals for smallx alignment ; ; procedure: ; The procedure takes the compare mask from zval to zbuffer and merge ; 4 pixels from the back buffer surface and the current color of the span. ; The new 4 pixel span is then copied back to the back buffer surface. ; The same thing is done for the zvalues. If the span is smaller than 4 pixels ; then scalar assembly is used to process the pixels. This version handles ; clamping in mmx but ignores it in the scalar assembly for spans with less ; than 4 pixels ;**************************************************************************** mmx_merge_zbuffer PROC C USES esi edi eax ebx ecx edx, smallx:DWORD,largex:DWORD,zval:DWORD,dz:DWORD, col:DWORD, zbuf:PTR WORD, dds:PTR WORD, mmxvars:PTR WORD mov edx, largex ; load largex - the end of the scan line mov ebx, smallx ; load smallx - the start of the scan line inc edx ; increment largex to include the last pixel mov eax, ebx ; copy smallx mov ecx, edx ; copy largex sub edx, ebx ; compute largex-smallx mov edi, dds ; load the pointer to the display surface cmp edx, 4 ; if largex-smallx<4 do scalar jb scalar_asm_ver ; jump to scalar assembly version and eax, 0fffch ; truncate lower two bits of smallx mov edx, ecx ; copy largex mov esi, zbuf ; load pointer to the z-buffer surface and ecx, 0fffch ; truncate lower two address bits of largex sub ecx, eax ; compute largex-smallx (aligned values) for loop variable push edx ; save largex to use in largex alignment movd mm0, zval ; load the z-value that corresponds to the start of the scan line punpcklwd mm0, mm0 ; unpack the zval into lower two words of mm0 mov edx, mmxvars ; load the pointer to the structure shl ebx, 3 ; multiply the misaligned address value by 8 ; this provides an offset to the correct mask punpckldq mm0, mm0 ; unpack the zval into the upper two words of mm0 paddw mm0, dword ptr [edx] ; add the dzs to each zval to create the first four zvals ; mm0=|zval+3dz|zval+2dz|zval+dz|zval| movq mm4, dword ptr [edx + 40]; load the 4 color values to mm4 movq mm7, mm0 ; copy the first four zvals and ebx, 18h ; truncate all but the lower two address bits of smallx ; these bits are converted to an offset for alignment masks jz main_pixel_loop ; if the lower 2 bits of smallx were zero, don't align smallx ;smallx_alignment: ; the goal of smallx alignment is to adjust the 4 zvals by subtracting dzs from each until zval is in the correct position ; this routine also loads the most positive signed value into positions where zval is not valid, ; this insures that those positions will not pass the compare in the main loop this prevents updating ; the display surface and z-buffer where the span isn't valid movq mm2, dword ptr [most_pos_mask] ; load mm2 with the maximum signed value for a word ;the above instr. needs to stay to prevent a AGI penalty psubsw mm0, dword ptr [edx + ebx]; subtract the correct number of dz to position zval movq mm5, dword ptr [ebx + sxmask0]; load the correct mask to AND the zvals with movq mm7, mm0 ; copy the new zvals pand mm7, mm5 ; AND compare mask with zvals pandn mm5, mm2 ; AND ~compare mask with neg mask values por mm7, mm5 ; combine valid zvals with neg values main_pixel_loop: ; the main pixel loop receives only aligned values for zvals, display surface pointer and z-buffer pointer ; the loop compares 4 zvals with the z-buffer to create a compare mask ; this mask is used to combine new values into z-buffer and combine new values to the offscreen display surface movq mm2,dword ptr [esi + 2*eax] ;move the zbuffer values to be compared to mm2 movq mm6, mm4 ;load the color values to mm6 movq mm5,dword ptr [esi + 2*eax] ; copy zbuf pcmpgtw mm2,mm7 ; create comparemask - zbuf>zval? movq mm3, mm2 ; copy the comparemask movq mm1, mm2 ; copy the comparemask pand mm6, mm2 ; AND comparemask with color pand mm2, mm0 ; AND comparemask with zval pandn mm1, dword ptr [edi + 2*eax]; AND ~comparemask with display surface pandn mm3, mm5 ; AND ~comparemask with zbuf paddsw mm0, dword ptr [edx + 32]; increment to get the next 4 zval por mm1, mm6 ; combine to make new display pixels add eax, 4 ; increment the smallx pointer por mm3, mm2 ; combine to make new zbuf values movq dword ptr [edi + 2*eax-8], mm1; update the display surface movq mm7, mm0 ; copy the new zval movq word ptr [esi + 2*eax-8], mm3; update the zbuffer with new values sub ecx, 4 ; decrement the loop variable jg main_pixel_loop ; loop back up to the top if not done largex_alignment: ; the goal of largex alignment is to load the most positive signed value into positions where zval is not valid, ; this insures that those positions will not pass the compare in the main loop, which is duplicated below ; this prevents updating the display surface and z-buffer where the span isn't valid pop ecx ; restore largex and ecx, 3 ; truncate all but the low 2 bits of largex jz all_done ; if the lower 2 bits of smallx were zero, no need to align largex shl ecx, 3 ; multiply the misaligned address value by 8 ; this provides an offset to the correct lxmask movq mm2, dword ptr [most_pos_mask] ; load mm2 with the maximum signed value for a word movq mm5, dword ptr [ecx + lxmask0] ; load the correct lxmask to AND the zvals with pand mm7, mm5 ; AND lxmask with zvals pandn mm5, mm2 ; AND ~lxmask with neg mask values movq mm2,dword ptr [esi + 2*eax] ;mov current zbuf values into mm2 por mm7, mm5 ; combine valid zvals with neg values movq mm5,dword ptr [esi + 2*eax] ; copy current zbuf values to mm5 pcmpgtw mm2,mm7 ; create compare mask - zval<zbuf movq mm3, mm2 ; copy the comparemask movq mm1, mm2 ; copy the comparemask pandn mm1, dword ptr [edi + 2*eax]; AND ~comparemask with display surface pand mm4, mm2 ; AND comparemask with color pandn mm3, mm5 ; AND ~comparemask with zbuf pand mm2, mm0 ; AND comparemask with zval por mm1, mm4 ; combine to make new display pixels por mm3, mm2 ; combine to make new zbuf values movq dword ptr [edi + 2*eax], mm1; update the display surface movq dword ptr [esi + 2*eax], mm3; update the zbuffer with new values ret ; all done so return scalar_asm_ver: mov eax, zval ; load the zval for smallx mov esi, zbuf ; load the pointer to the z-buffer mov ecx, col ; load the color value for this scan line single_pixel_loop: cmp ax, word ptr [esi + 2*ebx]; compare the zval with the z-buffer jg no_update if z-buffer < zval don't update the display or z-buffer mov word ptr [esi + 2*ebx], ax ; update the z-buffer mov word ptr [edi + 2*ebx], cx ; update the display surface no_update: add eax, dz ; increment to get the next zval inc ebx ; increment to the next scan line position dec edx ; decrement the loop counter jnz single_pixel_loop ; if the loop counter is not zero, jump to the top of the loop all_done: ret ; return mmx_merge_zbuffer EndP ;**************************************************************************** ; Transparent Pixel Algorithm for positive z axis going into the screen ; void mmx_trans_zbuffer ( long smallx, long largex, long zval, long dz, ; unsigned long col, short *zbuf,word *dds,short *mmxvar); ; ; vars: ; most variables are hold 16bit data but are passed as 32bit to prevent penalties in ; the scalar_asm function ; smallx - pixel offset for the start of the scan line ; largex - pixel offset for teh end of the scan line ; zval - the z-value for the first pixle in the span ; dz - amount to increment the initial zvalue with to genererate the next zvalue ; col - the 16-bit color value to be displayed for this polygon used in scalar asm ; zbuf - pointer to the start of this row in the z-buffer array ; dds - pointer to the start of this row in the offscreen surface ; mmxvars - an array of shorts which is loaded with the following: ; 0--------------------- ; |0 |1*dz|2*dz|3*dz| ; 8--------------------- ; |1*dz|1*dz|1*dz|1*dz| ; 16--------------------- ; |2*dz|2*dz|2*dz|2*dz| ; 24--------------------- ; |3*dz|3*dz|3*dz|3*dz| ; 32--------------------- ; |4*dz|4*dz|4*dz|4*dz| ; 40------------------------- ; |color|color|color|color| ; ------------------------- ; ; eax - aligned smallx ; ebx - smallx ; ecx - aligned largex-smallx ; edx - largex ; esi - pointer to the z-buffer ; edi - pointer to the offscreen surface ; mm0 - the 4 z-values to compare with z-buffer ; mm1 - a copy of the compare mask ; mm2 - holds zbuffer values and later compare masks ; mm3 - a copy of the compare mask ; mm4 - holds the four copies of the polygon color ; mm5 - misc. functions ; mm6 - copy of mm4 used with compare mask ; mm7 - holds mm0 with modified zvals for smallx alignment ; ; procedure: ; The procedure takes the compare mask from zval to zbuffer and merge ; 4 pixels from the back buffer surface and the current color of the span. ; The new 4 pixel span is then copied back to the back buffer surface. ; The same thing is done for the zvalues. If the span is smaller than 4 pixels ; then scalar assembly is used to process the pixels. This version handles ; clamping in mmx but ignores it in the scalar assembly for spans with less ; than 4 pixels ;**************************************************************************** mmx_trans_zbuffer PROC C USES esi edi eax ebx ecx edx, smallx:DWORD,largex:DWORD,zval:DWORD,dz:DWORD, col:DWORD, zbuf:PTR WORD, dds:PTR WORD, mmxvars:PTR WORD mov edx, largex ; load largex - the end of the scan line mov ebx, smallx ; load smallx - the start of the scan line inc edx ; increment largex to include the last pixel mov eax, ebx ; copy smallx mov ecx, edx ; copy largex sub edx, ebx ; compute largex-smallx mov edi, dds ; load the pointer to the display surface cmp edx, 4 ; if largex-smallx<4 do scalar jb scalar_asm_ver ; jump to scalar assembly version and eax, 0fffch ; truncate lower two bits of smallx mov edx, ecx ; copy largex mov esi, zbuf ; load pointer to the z-buffer surface and ecx, 0fffch ; truncate lower two address bits of largex sub ecx, eax ; compute largex-smallx (aligned values) for loop variable push edx ; save largex to use in largex alignment movd mm0,zval ; load the z-value that corresponds to the start of the scan line mov edx, mmxvars ; load the pointer to the structure punpcklwd mm0, mm0 ; unpack the zval into lower two words of mm0 shl ebx, 3 ; multiply the misaligned address value by 8 ; this provides an offset to the correct mask punpckldq mm0, mm0 ; unpack the zval into the upper two words of mm0 paddsw mm0, dword ptr [edx] ; add the dzs to each zval to create the first four zvals ; mm0=|zval+3dz|zval+2dz|zval+dz|zval| movq mm4, dword ptr [edx + 40]; load the 4 color values to mm4 movq mm7, mm0 ; copy the first four zvals movq mm1,dword ptr [edx + 32]; move 4 zval into mm1 and ebx, 18h ; truncate all but the lower two address bits of smallx ; these bits are converted to an offset for alignment masks jz main_pixel_loop ; if the lower 2 bits of smallx were zero, don't align smallx ;smallx_alignment: ; the goal of smallx alignment is to adjust the 4 zvals by subtracting dzs from each until zval is in the correct position ; this routine also loads the most positive signed value into positions where zval is not valid, ; this insures that those positions will not pass the compare in the main loop this prevents updating ; the display surface and z-buffer where the scan line isn't valid movq mm2, dword ptr [most_pos_mask] ; load mm2 with the maximum signed value for a word ;the above instruction needs to stay to prevent a AGI with ebx psubsw mm0, dword ptr [edx + ebx] ; subtract the correct number of dz to position zval movq mm5, dword ptr [ebx + sxmask0] ; load the correct mask to AND the zvals with movq mm7, mm0 ; copy the new zvals pand mm7, mm5 ; AND compare mask with zvals pandn mm5, mm2 ; AND ~compare mask with neg mask values por mm7, mm5 ; combine valid zvals with neg values main_pixel_loop: ; the main pixel loop receives only aligned values for zvals, display surface pointer and z-buffer pointer ; the loop compares 4 zvals with the z-buffer to create a compare mask ; this mask is used to combine new values into z-buffer and combine new values to the offscreen display surface movq mm2,dword ptr [esi + 2*eax] ;mov zbuffer values to mm2 movq mm6, mm4 ;load the color values to mm6 movq mm5,dword ptr [esi + 2*eax] ; mov zbuffer values to mm5 pcmpgtw mm2,mm7 ; create comparemask - zbuf>zval? movq mm3, mm2 ; copy the comparemask pand mm6, mm2 ; AND comparemask with color pandn mm3, mm5 ; AND ~comparemask with zbuf pand mm2, mm0 ; AND comparemask with zval movq dword ptr [edi + 2*eax], mm6; update the display surface por mm3, mm2 ; combine to make new zbuf values paddsw mm0, mm1 ; increment to get the next 4 zval add eax, 4 ; increment the smallx pointer movq dword ptr [esi + 2*eax-8], mm3; update the zbuffer with new values movq mm7, mm0 ; copy the new zval sub ecx, 4 ; decrement the loop variable jg main_pixel_loop ; loop back up to the top if not done largex_alignment: ; the goal of largex alignment is to load the most positive signed value into positions where zval is not valid, ; this insures that those positions will not pass the compare in the main loop, which is duplicated below ; this prevents updating the display surface and z-buffer where the scan line isn't valid pop ecx ; restore largex and ecx, 3 ; truncate all but the low 2 bits of largex jz all_done ; if the lower 2 bits of smallx were zero, no need to align largex shl ecx, 3 ; multiply the misaligned address value by 8 ; this provides an offset to the correct lxmask movq mm1, dword ptr [most_pos_mask] ; load mm2 with the maximum signed value for a word movq mm5, dword ptr [ecx + lxmask0] ; load the correct lxmask pand mm7, mm5 ; AND lxmask with zvals pandn mm5, mm1 ; AND ~lxmask with most pos mask values movq mm2,dword ptr [esi + 2*eax] ;mov current zbuf values into mm2 por mm7, mm5 ; combine valid zvals with most pos mask values movq mm6,dword ptr [esi + 2*eax] ; copy current zbuf values to mm6 pcmpgtw mm2,mm7 ; create compare mask - zbuf>zval pand mm4, mm2 ; AND comparemask with color movq mm3, mm2 ; copy the comparemask pandn mm3, mm6 ; AND ~comparemask with zbuf pand mm2, mm0 ; AND comparemask with zval movq dword ptr [edi + 2*eax], mm4; update the display surface por mm3, mm2 ; combine to make new zbuf values movq dword ptr [esi + 2*eax], mm3; update the zbuffer with new values ret ; all done so return scalar_asm_ver: mov eax, zval ; load the zval for smallx mov esi, zbuf ; load the pointer to the z-buffer mov ecx, col ; load the color value for this scan line single_pixel_loop: cmp ax, word ptr [esi + 2*ebx]; compare the zval with the z-buffer jg no_update ; if z-buffer < zval don't update the display or z-buffer mov word ptr [esi + 2*ebx], ax ; update the z-buffer mov word ptr [edi + 2*ebx], cx ; update the display surface no_update: add eax, dz ; increment to get the next zval inc ebx ; increment to the next scan line position dec edx ; decrement the loop counter jnz single_pixel_loop ; if the loop counter is not zero, jump to the top of the loop all_done: ret ; return mmx_trans_zbuffer EndP ELSE ;else conditional assembly ;**************************************************************************** ; The following versions of mmx zbuffer is used when the positive z ; axis points out of the screen. 32K is at the screen and receeds to ; -32K in the distance. ;**************************************************************************** mmx_merge_zbuffer PROC C USES esi edi eax ebx ecx edx, smallx:DWORD,largex:DWORD,zval:DWORD,dz:DWORD, col:DWORD, zbuf:PTR WORD, dds:PTR WORD, mmxvars:PTR WORD mov edx, largex ; load largex - the end of the scan line mov ebx, smallx ; load smallx - the start of the scan line inc edx ; increment largex to include the last pixel mov eax, ebx ; copy smallx mov ecx, edx ; copy largex sub edx, ebx ; compute largex-smallx mov edi, dds ; load the pointer to the display surface cmp edx, 4 ; if largex-smallx<4 do scalar jb scalar_asm_ver ; jump to scalar assembly version and eax, 0fffch ; truncate lower two bits of smallx mov edx, ecx ; copy largex mov esi, zbuf ; load pointer to the z-buffer surface and ecx, 0fffch ; truncate lower two address bits of largex sub ecx, eax ; compute largex-smallx (aligned values) for loop variable push edx ; save largex to use in largex alignment movd mm0, zval ; load the z-value that corresponds to the start of the scan line punpcklwd mm0, mm0 ; unpack the zval into lower two words of mm0 mov edx, mmxvars ; load the pointer to the structure shl ebx, 3 ; multiply the misaligned address value by 8 ; this provides an offset to the correct mask punpckldq mm0, mm0 ; unpack the zval into the upper two words of mm0 paddw mm0, dword ptr [edx] ; add the dzs to each zval to create the first four zvals ; mm0=|zval+3dz|zval+2dz|zval+dz|zval| movq mm4, dword ptr [edx + 40]; load the 4 color values to mm4 movq mm7, mm0 ; copy the first four zvals movq mm1,dword ptr [edx + 32]; move 4 zval into mm1 and ebx, 18h ; truncate all but the lower two address bits of smallx ; these bits are converted to an offset for alignment masks jz main_pixel_loop ; if the lower 2 bits of smallx were zero, don't align smallx ;smallx_alignment: ; the goal of smallx alignment is to adjust the 4 zvals by subtracting dzs from each until zval is in the correct position ; this routine also loads the most negative signed value into positions where zval is not valid, ; this insures that those positions will not pass the compare in the main loop this prevents updating ; the display surface and z-buffer where the span isn't valid movq mm2, dword ptr [most_neg_mask] ; load mm2 with the minimum signed value for a word ;the above instr. needs to stay to prevent a AGI penalty psubsw mm0, dword ptr [edx + ebx] ; subtract the correct number of dz to position zval movq mm5, dword ptr [ebx + sxmask0] ; load the correct mask to AND the zvals with movq mm7, mm0 ; copy the new zvals pand mm7, mm5 ; AND compare mask with zvals pandn mm5, mm2 ; AND ~compare mask with neg mask values por mm7, mm5 ; combine valid zvals with neg values main_pixel_loop: ; the main pixel loop receives only aligned values for zvals, display surface pointer and z-buffer pointer ; the loop compares 4 zvals with the z-buffer to create a compare mask ; this mask is used to combine new values into z-buffer and combine new values to the offscreen display surface movq mm2,dword ptr [esi + 2*eax] ;move the zbuffer values to be compared to mm2 movq mm6, mm4 ;load the color values to mm6 pcmpgtw mm7,mm2 ; create comparemask - zval>zbuf? add eax, 4 ; increment the smallx pointer movq mm3, mm7 ; copy the comparemask pand mm6, mm7 ; AND comparemask with color movq mm5, mm7 ; copy the comparemask pandn mm3, mm2 ; AND ~comparemask with zbuf pandn mm5, dword ptr [edi + 2*eax-8]; AND ~comparemask with display surface por mm5, mm6 ; combine to make new display pixels pand mm7, mm0 ; AND comparemask with zval paddsw mm0, mm1 ; increment to get the next 4 zval movq dword ptr [edi + 2*eax-8], mm5; update the display surface por mm3, mm7 ; combine to make new zbuf values movq dword ptr [esi + 2*eax-8], mm3; update the zbuffer with new values movq mm7, mm0 ; copy the new zval sub ecx, 4 ; decrement the loop variable jg main_pixel_loop ; loop back up to the top if not done largex_alignment: ; the goal of largex alignment is to load the most negartive signed value into positions where zval is not valid, ; this insures that those positions will not pass the compare in the main loop, which is duplicated below ; this prevents updating the display surface and z-buffer where the span isn't valid pop ecx ; restore largex and ecx, 3 ; truncate all but the low 2 bits of largex jz all_done ; if the lower 2 bits of smallx were zero, no need to align largex shl ecx, 3 ; multiply the misaligned address value by 8 ; this provides an offset to the correct lxmask movq mm2, dword ptr [most_neg_mask] ; load mm2 with the minimum signed value for a word movq mm5, dword ptr [ecx + lxmask0] ; load the correct lxmask to AND the zvals with pand mm7, mm5 ; AND lxmask with zvals pandn mm5, mm2 ; AND ~lxmask with neg mask values movq mm2,dword ptr [esi + 2*eax] ;mov current zbuf values into mm2 por mm7, mm5 ; combine valid zvals with neg values pcmpgtw mm7,mm2 ; create compare mask - zval>zbuf movq mm3, mm7 ; copy the comparemask movq mm1, mm7 ; copy the comparemask pandn mm1, dword ptr [edi + 2*eax]; AND ~comparemask with display surface pand mm4, mm7 ; AND comparemask with color pandn mm3, mm2 ; AND ~comparemask with zbuf pand mm7, mm0 ; AND comparemask with zval por mm1, mm4 ; combine to make new display pixels por mm3, mm7 ; combine to make new zbuf values movq dword ptr [edi + 2*eax], mm1; update the display surface movq dword ptr [esi + 2*eax], mm3; update the zbuffer with new values ret ; all done so return scalar_asm_ver: mov eax, zval ; load the zval for smallx mov esi, zbuf ; load the pointer to the z-buffer mov ecx, col ; load the color value for this scan line single_pixel_loop: cmp ax, word ptr [esi + 2*ebx]; compare the zval with the z-buffer jl no_update ; if z-buffer > zval don't update the display or z-buffer mov word ptr [esi + 2*ebx], ax; update the z-buffer mov word ptr [edi + 2*ebx], cx; update the display surface no_update: add eax, dz ; increment to get the next zval inc ebx ; increment to the next scan line position dec edx ; decrement the loop counter jnz single_pixel_loop ; if the loop counter is not zero, jump to the top of the loop all_done: ret ; return mmx_merge_zbuffer EndP mmx_trans_zbuffer PROC C USES esi edi eax ebx ecx edx, smallx:DWORD,largex:DWORD,zval:DWORD,dz:DWORD, col:DWORD, zbuf:PTR WORD, dds:PTR WORD, mmxvars:PTR WORD mov edx, largex ; load largex - the end of the scan line mov ebx, smallx ; load smallx - the start of the scan line inc edx ; increment largex to include the last pixel mov eax, ebx ; copy smallx mov ecx, edx ; copy largex sub edx, ebx ; compute largex-smallx mov edi, dds ; load the pointer to the display surface cmp edx, 4 ; if largex-smallx<4 do scalar jb scalar_asm_ver ; jump to scalar assembly version and ax, 0fffch ; truncate lower two bits of smallx mov edx, ecx ; copy largex mov esi, zbuf ; load pointer to the z-buffer surface and ecx, 0fffch ; truncate lower two address bits of largex sub ecx, eax ; compute largex-smallx (aligned values) for loop variable push edx ; save largex to use in largex alignment movd mm0,zval ; load the z-value that corresponds to the start of the scan line mov edx, mmxvars ; load the pointer to the structure punpcklwd mm0, mm0 ; unpack the zval into lower two words of mm0 shl ebx, 3 ; multiply the misaligned address value by 8 ; this provides an offset to the correct mask punpckldq mm0, mm0 ; unpack the zval into the upper two words of mm0 paddsw mm0, dword ptr [edx] ; add the dzs to each zval to create the first four zvals ; mm0=|zval+3dz|zval+2dz|zval+dz|zval| movq mm4, dword ptr [edx + 40]; load the 4 color values to mm4 movq mm7, mm0 ; copy the first four zvals movq mm1,dword ptr [edx + 32]; move 4 zval into mm1 and ebx, 18h ; truncate all but the lower two address bits of smallx ; these bits are converted to an offset for alignment masks jz main_pixel_loop ; if the lower 2 bits of smallx were zero, don't align smallx ;smallx_alignment: ; the goal of smallx alignment is to adjust the 4 zvals by subtracting dzs from each until zval is in the correct position ; this routine also loads the most negative signed value into positions where zval is not valid, ; this insures that those positions will not pass the compare in the main loop this prevents updating ; the display surface and z-buffer where the scan line isn't valid movq mm2, dword ptr [most_neg_mask] ; load mm2 with the minimum signed value for a word ;the above instruction needs to stay to prevent a AGI with ebx psubsw mm0, dword ptr [edx + ebx] ; subtract the correct number of dz to position zval movq mm5, dword ptr [ebx + sxmask0] ; load the correct mask to AND the zvals with movq mm7, mm0 ; copy the new zvals pand mm7, mm5 ; AND compare mask with zvals pandn mm5, mm2 ; AND ~compare mask with neg mask values por mm7, mm5 ; combine valid zvals with neg values main_pixel_loop: ; the main pixel loop receives only aligned values for zvals, display surface pointer and z-buffer pointer ; the loop compares 4 zvals with the z-buffer to create a compare mask ; this mask is used to combine new values into z-buffer and combine new values to the offscreen display surface movq mm2,dword ptr [esi + 2*eax] ;mov zbuffer values to mm2 movq mm6, mm4 ;load the color values to mm6 pcmpgtw mm7,mm2 ; create comparemask - zval>zbuf? add eax, 4 ; increment the smallx pointer movq mm3, mm7 ; copy the comparemask pand mm6, mm7 ; AND comparemask with color pandn mm3, mm2 ; AND ~comparemask with zbuf pand mm7, mm0 ; AND comparemask with zval movq dword ptr [edi + 2*eax-8], mm6; update the display surface por mm3, mm7 ; combine to make new zbuf values paddsw mm0, mm1 ; increment to get the next 4 zval sub ecx, 4 ; decrement the loop variable movq dword ptr [esi + 2*eax-8], mm3; update the zbuffer with new values movq mm7, mm0 ; copy the new zval jg main_pixel_loop ; loop back up to the top if not done largex_alignment: ; the goal of largex alignment is to load the most negative signed value into positions where zval is not valid, ; this insures that those positions will not pass the compare in the main loop, which is duplicated below ; this prevents updating the display surface and z-buffer where the scan line isn't valid pop ecx ; restore largex and ecx, 3 ; truncate all but the low 2 bits of largex jz all_done ; if the lower 2 bits of smallx were zero, no need to align largex shl ecx, 3 ; multiply the misaligned address value by 8 ; this provides an offset to the correct lxmask movq mm1, dword ptr [most_neg_mask] ; load mm2 with the minimum signed value for a word movq mm5, dword ptr [ecx + lxmask0] ; load the correct lxmask pand mm7, mm5 ; AND lxmask with zvals pandn mm5, mm1 ; AND ~lxmask with most pos mask values movq mm2,dword ptr [esi + 2*eax] ;mov current zbuf values into mm2 por mm7, mm5 ; combine valid zvals with most pos mask values pcmpgtw mm7,mm2 ; create compare mask - zval>zbuf? pand mm4, mm7 ; AND comparemask with color movq mm3, mm7 ; copy the comparemask pandn mm3, mm2 ; AND ~comparemask with zbuf pand mm7, mm0 ; AND comparemask with zval movq dword ptr [edi + 2*eax], mm4; update the display surface por mm3, mm7 ; combine to make new zbuf values movq dword ptr [esi + 2*eax], mm3 ; update the zbuffer with new values ret ; all done so return scalar_asm_ver: mov eax, zval ; load the zval for smallx mov esi, zbuf ; load the pointer to the z-buffer mov ecx, col ; load the color value for this scan line single_pixel_loop: cmp ax, word ptr [esi + 2*ebx] ; compare the zval with the z-buffer jl no_update ; if z-buffer > zval don't update the display or z-buffer mov word ptr [esi + 2*ebx], ax ; update the z-buffer mov word ptr [edi + 2*ebx], cx ; update the display surface no_update: add eax, dz ; increment to get the next zval inc ebx ; increment to the next scan line position dec edx ; decrement the loop counter jnz single_pixel_loop ; if the loop counter is not zero, jump to the top of the loop all_done: ret mmx_trans_zbuffer EndP ENDIF END


